-
Welcome! The TrekBBS is the number one place to chat about Star Trek with like-minded fans.
If you are not already a member then please register an account and join in the discussion!
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Star Trek AI art thread
- Thread starter F. King Daniel
- Start date
C
Captain pl1ngpl0ng
Guest
There are offline image generators? I like things not reliant on the internet for constant operations, especially with potentially dodgy persistent connections. Where do these exist? Are they available anywhere for download?
you need to jump trough some hoops but here is the only youtube video that explain the whole thing.
nb; you do need a nvidia graphic card with at least 6gbvram, 8 is good, but more is better.
There was some discussion earlier this year about how AI can reproduce art from the training data if you give it an exactly matching description for a prompt.
even if you describe an image exactly(if thats possible), you will get totaly different images based on the random seed number even if you use the exact same description. you can probably get pretty close when trying to get mona lisa but it's highly unlikely you can get the exact mirror image.
EDIT_I'm no expert.... i might be totaly wrong
To anyone who is interested
Ai does NOT copy parts of images from the interent, mixing them together and creating a new image.
This is NOT how it works...
Ai are only TRAINED on images from the internet and how they look, it does not copy....
How is it trained?
it learned how an image gradually change from an image to an unrecognizable soup of random noise (diffusion of an image),
After training, the ai have a noise predictor capable of estimating the noise added to an image.
quote:
"
1.Pick a training image, like a photo of a cat.
2.Generate a random noise image.then..
3.Corrupt the training image by adding this noisy image up to a certain number of steps.
4.Teach the noise predictor to tell us how much noise was added. This is done by tuning its weights and showing it the correct answer.
"
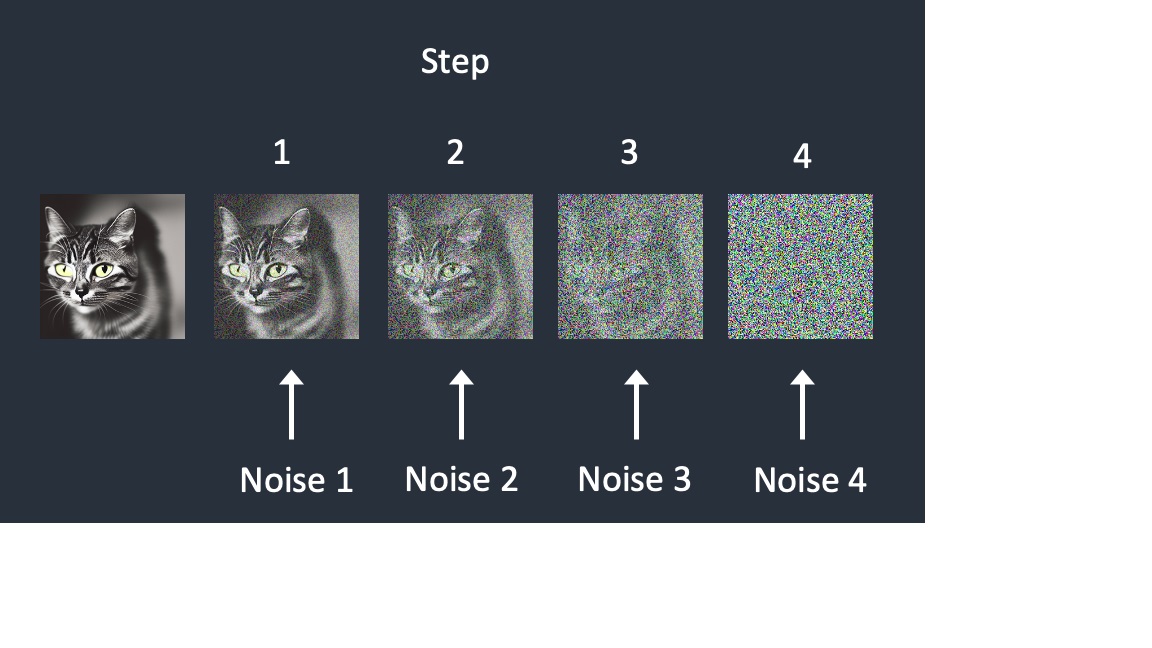
Now the AI can do a reverse diffusion.
From our text input/prompt it uses the noise predictor to estimate how much noise needed to subtract from each step to make an image.
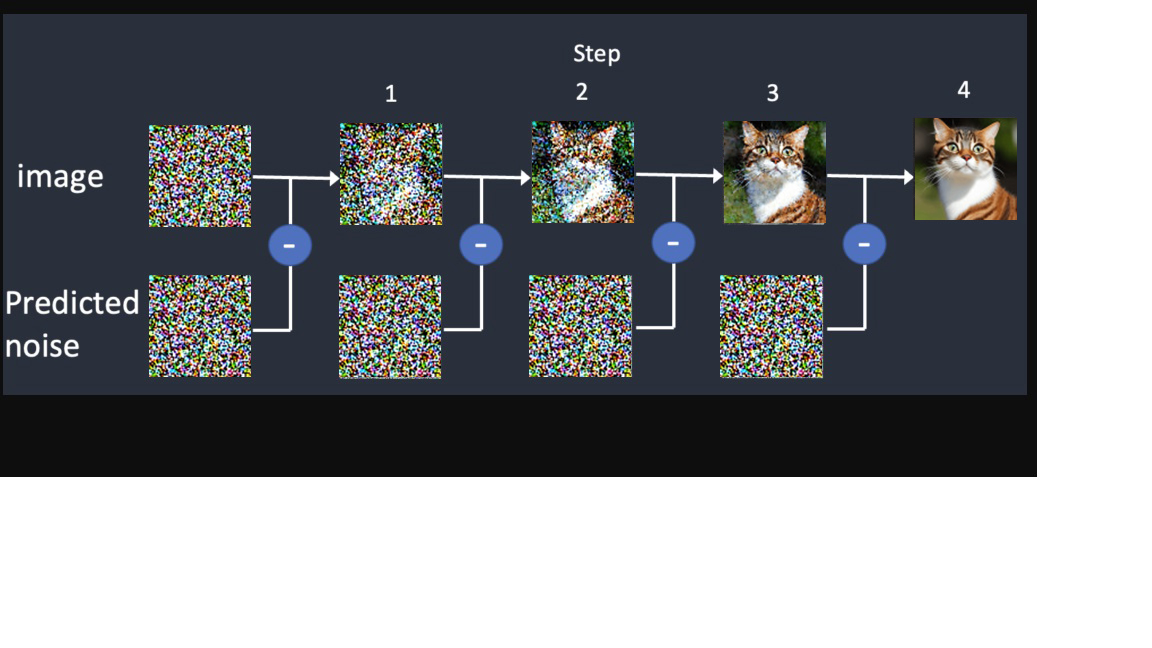
the image produced does NOT come from any parts of artwork grabbed from the internet,
the image is simply created.
and here is a big point: I can run the ai locally without any internet connection!
That is because ai does not store images, it store the informaition about how to create them.
think of it like this:
when you do math like 6-2=4 and 4+4=8 etc.....
you dont store/remember every answer on every possible equation, you just remember the methode.
EDIT: an in depth link: https://stable-diffusion-art.com/how-stable-diffusion-work/
From reading through your in depth link we can see that it can reverse diffusion back to the training image.
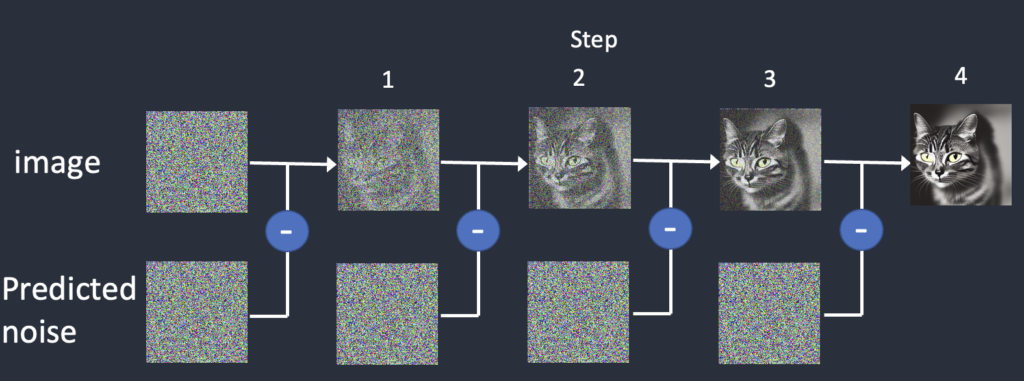
According to the article, stable diffusion's trained data is heavily compressed so that it can be portable. I would imagine that if the training data was limited to just one cat, you can recreate only just that cat. The more samples you have, the more combinations it can come up with but essentially those combinations are based on the training data.
It doesn't sound like it is storing an image as a method but instead a pattern that can be reversed back to the original (or a fuzzy version because of the compression).
C
Captain pl1ngpl0ng
Guest
From reading through your in depth link we can see that it can reverse diffusion back to the training image.
i think you are wrong and this is just an image of a cat they used to show both forward and reverse, they did include this gif to show the actual transformation:
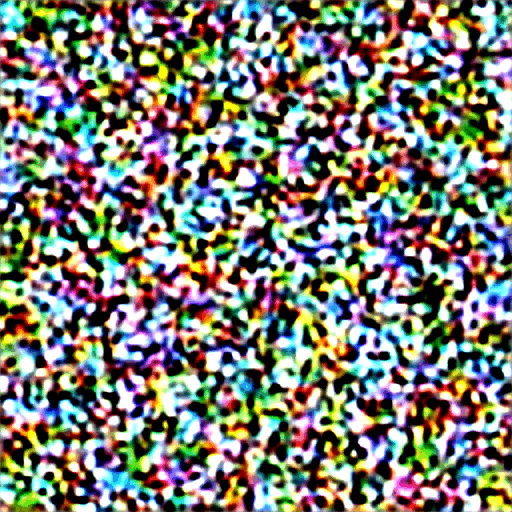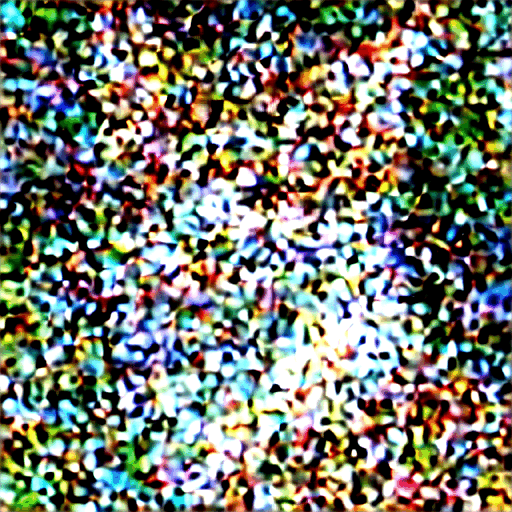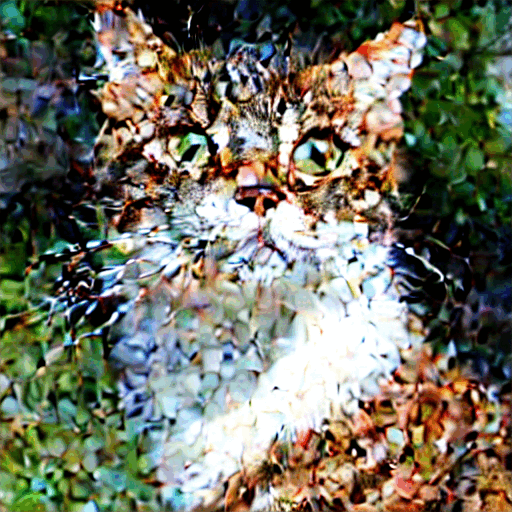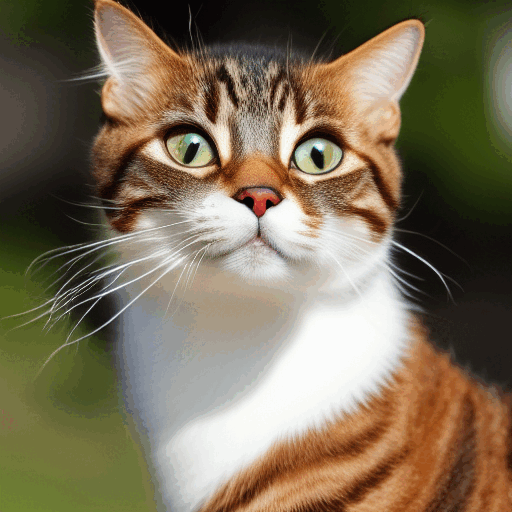
C
Captain pl1ngpl0ng
Guest
i dont think it store a pattern ..... this is a complex thing, .... i have no idea on how it REALLY works down to every detail of the process... i dont think very many people do tbh.It doesn't sound like it is storing an image as a method but instead a pattern that can be reversed back to the original (or a fuzzy version because of the compression).
C
Captain pl1ngpl0ng
Guest
this is a good point.....I would imagine that if the training data was limited to just one cat, you can recreate only just that cat
https://arstechnica.com/information...ages-from-stable-diffusion-but-its-difficult/
I've tried it myself with their example in Stable Diffusion, it happens, but only sometimes, and happens more consistently if you include the entire caption, not just her name. Unfortunately they didn't include more examples of image descriptions to try. Using other models it's hit and miss, probably related to how closely related to Stable Diffusion they are, and how much they have expanded their training set. The larger the set the less likely this is.
Also this quirk is duplication of the entire exact image, which is different from pulling elements from several pictures and putting them together, which, as we have discussed, is not how this stuff works.
I've tried it myself with their example in Stable Diffusion, it happens, but only sometimes, and happens more consistently if you include the entire caption, not just her name. Unfortunately they didn't include more examples of image descriptions to try. Using other models it's hit and miss, probably related to how closely related to Stable Diffusion they are, and how much they have expanded their training set. The larger the set the less likely this is.
Also this quirk is duplication of the entire exact image, which is different from pulling elements from several pictures and putting them together, which, as we have discussed, is not how this stuff works.
C
Captain pl1ngpl0ng
Guest
yes thats why it doesnt matter "IF" it was trained on only ONE image, because thats not what happened in real life.The larger the set the less likely this is.
i think you are wrong and this is just an image of a cat they used to show both forward and reverse, they did include this gif to show the actual transformation:
The article has graphics that illustrate it can go back to the original image. The image below is straight from the article:
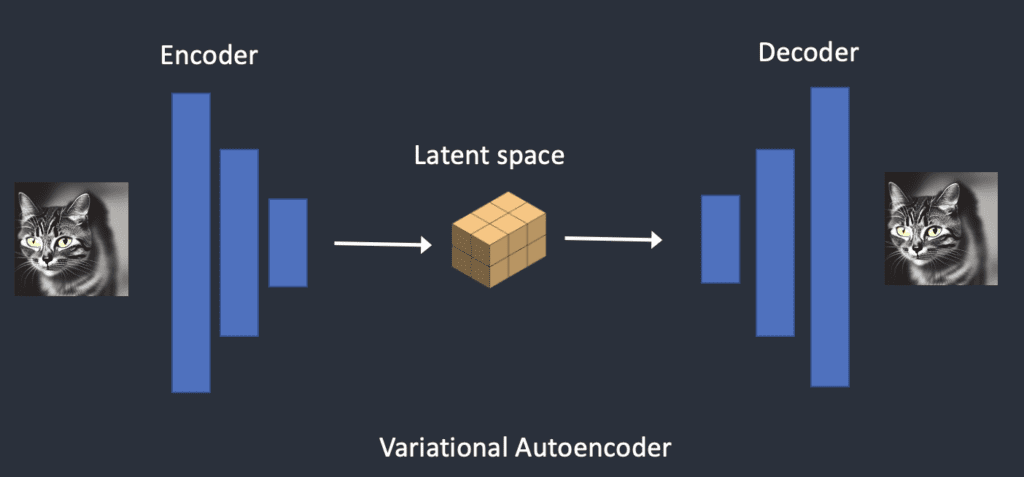
As described in the article, the training data, for example this cute cat, is encoded into this compressed format with noise that stable diffusion uses. It is lossy but it can be decoded back to a fuzzy version of the original cat if given the same conditions that added that noise.
Text prompts essentially are used to steer the noise removal so it isn't as randomized a decoding.
If you have a large enough number of trained images and a broad text prompt you could potentially never tell which images are contributing to the generated image. But you can tell if there is a certain bias like if you trained on a majority of ginger cats you're going to get mostly ginger cats. That seems to be how stable diffusion and these other generative ai companies are obfuscating the training data. It only becomes obvious in cases where the prompt is so unique (like in @UssGlenn 's arstechnica article) that we can see the training data is not a "process" but just highly compressed images that are fuzzed together to produce a new image.
I can see why artists want to be compensated for their artwork being used as training data as the generator wouldn't work without their artwork contributing to that variation the generator needs. IMHO.
C
Captain pl1ngpl0ng
Guest
ah ok,
anyway, this would only be a problem if the ai was trained on 1 image. but it is trained on millions and billions..... i understand that some just cant see the value of this tool. if i was an artist i would train a Lora or a Model with my own images, and then use the ai to come up with concepts for me, in my own style and capability.
anyway, this would only be a problem if the ai was trained on 1 image. but it is trained on millions and billions..... i understand that some just cant see the value of this tool. if i was an artist i would train a Lora or a Model with my own images, and then use the ai to come up with concepts for me, in my own style and capability.
I literally have no idea what any of that means, but it seems to work, so... 

Well this random thing did happen when I was trying for something else:There was some discussion earlier this year about how AI can reproduce art from the training data if you give it an exactly matching description for a prompt.


ah ok,
anyway, this would only be a problem if the ai was trained on 1 image. but it is trained on millions and billions..... i understand that some just cant see the value of this tool. if i was an artist i would train a Lora or a Model with my own images, and then use the ai to come up with concepts for me, in my own style and capability.
Sure, if you deleted all the training data and just used your own images then there is no issue. It is the training data from all the millions and billions of copyrighted images...
There's a transporter effect right therei think you are wrong and this is just an image of a cat they used to show both forward and reverse, they did include this gif to show the actual transformation:
More
https://techxplore.com/news/2023-11-realistic-ai-powered.html
Last edited:
C
Captain pl1ngpl0ng
Guest
well... it's nice to have a discussion, i like that. i don't think we are going to agree, but i also realize it's both good and bad sides with this technology. let's look at something good? :
there is nothing better than ai to upscale your artwork, it doesn't need to be ai generated either,
if you have made an image and you wish you had worked on a higher rez because it turned out a masterpiece...
then do this: (stable diffusion)
(most people use the "extra tab" and use an upscaler in there, it does a good job, much better than photoshop
but still it is not great... )
here is great:
1.
drag your image into the "img2img tab" lets say you have worked in 512x512 pixels
you can hit the "interrogate clip" button to get a description(promt) for your image if it's not ai generated.
mine IS ai and i used something like this: "analog fujifilm photo of Uhura from star trek, star trek uniform, (portrait upper body), sci fi environment, dark hair, detailed skin, detailed eyes, realistic eyes, 20 megapixel, detailed skin, detailed face
"

then go to "script/SD upscale from here choose "4x-UltraSharp" you might need to download that particular upscaler if you dont have it ( yes it's a free add-on for stable diffusion )
choose a "Denoising strength" of maximum 0.35 (any more and the ai will get too creative as it adds small details to keep the artwork super sharp during the process)
and use a Scale Factor of 2, hit the generate button...
(i am cropping these images, they are going to be huge)
Your image is now 1024x1024

2. now drag this new image into the same place you had the original and repeat the upscaling
your image at 2048:

the ai is adding small details every time you upscale so you should reduce the Denoise Strength to around 0.25 now
also, if you get artifact like i did here

if ai is adding a extra face on the shirt.or something.then just delete the word "face" from the prompt and everything should be fine.
now repeat the process again to scale it up to 4096x4096

on this last upscale to get the picture up to 8k, i reduced the denoise to about 0.19 ..
8192x8192 pixels :
closeup of eye

closeup of hair strands

this is the best way i know of to upscale an image without loosing details and sharpness.
Maybe something new and better have come along? i still use SD 1.5 so i dont know,but this methode works great.
there is nothing better than ai to upscale your artwork, it doesn't need to be ai generated either,
if you have made an image and you wish you had worked on a higher rez because it turned out a masterpiece...
then do this: (stable diffusion)
(most people use the "extra tab" and use an upscaler in there, it does a good job, much better than photoshop
but still it is not great... )
here is great:
1.
drag your image into the "img2img tab" lets say you have worked in 512x512 pixels
you can hit the "interrogate clip" button to get a description(promt) for your image if it's not ai generated.
mine IS ai and i used something like this: "analog fujifilm photo of Uhura from star trek, star trek uniform, (portrait upper body), sci fi environment, dark hair, detailed skin, detailed eyes, realistic eyes, 20 megapixel, detailed skin, detailed face
"
then go to "script/SD upscale from here choose "4x-UltraSharp" you might need to download that particular upscaler if you dont have it ( yes it's a free add-on for stable diffusion )
choose a "Denoising strength" of maximum 0.35 (any more and the ai will get too creative as it adds small details to keep the artwork super sharp during the process)
and use a Scale Factor of 2, hit the generate button...
(i am cropping these images, they are going to be huge)
Your image is now 1024x1024
2. now drag this new image into the same place you had the original and repeat the upscaling
your image at 2048:
the ai is adding small details every time you upscale so you should reduce the Denoise Strength to around 0.25 now
also, if you get artifact like i did here
if ai is adding a extra face on the shirt.or something.then just delete the word "face" from the prompt and everything should be fine.
now repeat the process again to scale it up to 4096x4096
on this last upscale to get the picture up to 8k, i reduced the denoise to about 0.19 ..
8192x8192 pixels :
closeup of eye
closeup of hair strands
this is the best way i know of to upscale an image without loosing details and sharpness.
Maybe something new and better have come along? i still use SD 1.5 so i dont know,but this methode works great.
There does seem to be a kind of unnatural softness to many of these AI-generated images. Almost like they were made or done-over by an airbrush. Close-ups of faces don't show pores, blemishes and other human "flaws" (a poor word to use, I know, but for lack of a better term...) I suspect they'll have that easily worked out in the near future, however. The results are quite stunning by any measure.
C
Captain pl1ngpl0ng
Guest
^ i didnt think of that.... but the image was soft from the start, i must play around with this and see if natural skin can get a good upscaling!
C
Captain pl1ngpl0ng
Guest
There does seem to be a kind of unnatural softness to many of these AI-generated images. Almost like they were made or done-over by an airbrush. Close-ups of faces don't show pores, blemishes and other human "flaws" (a poor word to use, I know, but for lack of a better term...) I suspect they'll have that easily worked out in the near future, however. The results are quite stunning by any measure.
you are quite right, following my steps here the upscaling really smeared everything out
but after getting it up to 1024 i switched to the "extras" tab and upscaled it x2 every step there.
the difference was surprising to me...
original

4k detail and my first solution to the left....it really didn't work on natural skin as you said.
so to get a good result you need to jump around a little and test different methodes.
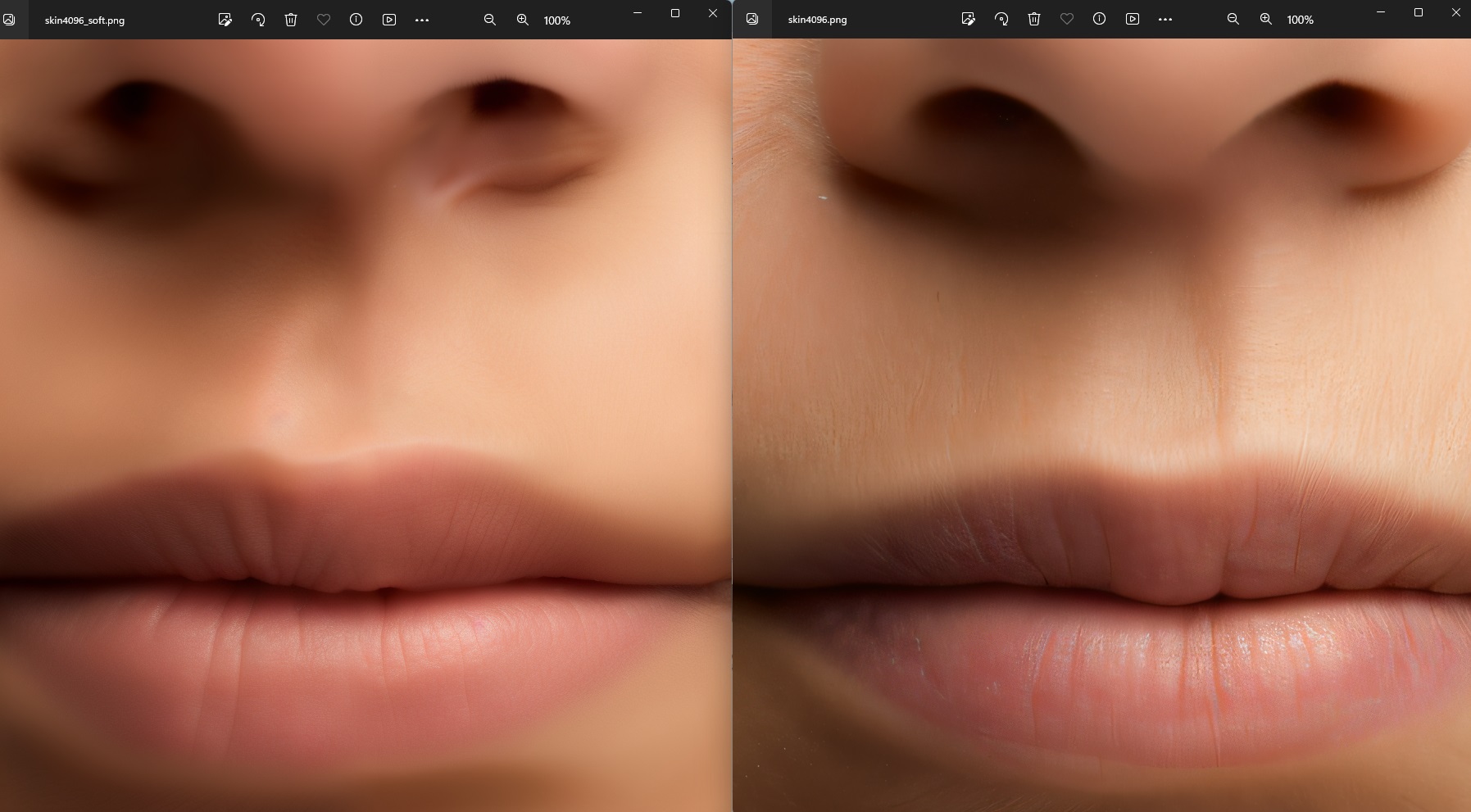
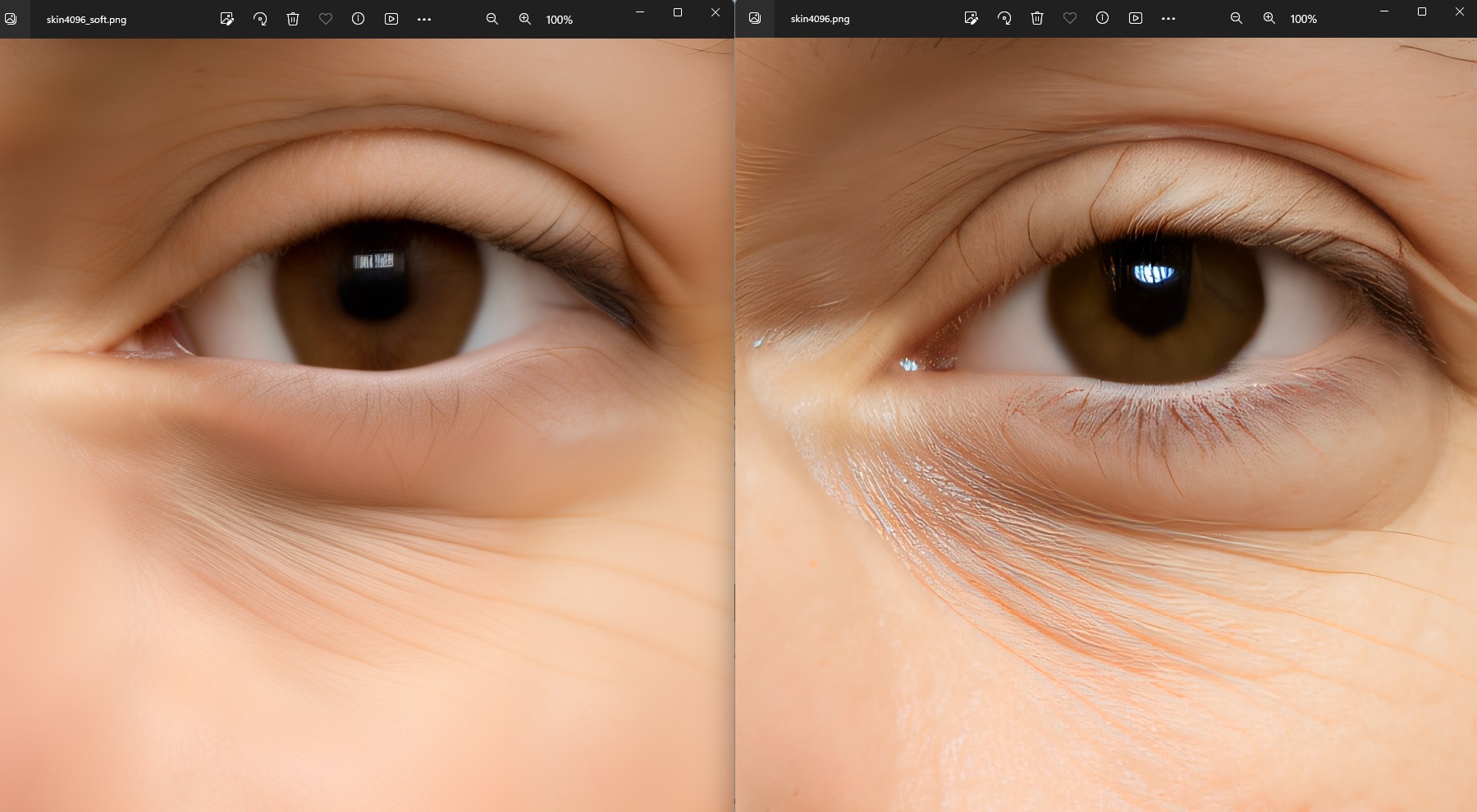
so jumping over to the "extras tab" and upscale the rest from there did the trick.
I learned something new!
YES! That's starting to look a lot more real now.
Scary real...
Scary real...
C
Captain pl1ngpl0ng
Guest

Similar threads
- Replies
- 2
- Views
- 103
- Replies
- 2
- Views
- 347
- Replies
- 5
- Views
- 805
If you are not already a member then please register an account and join in the discussion!