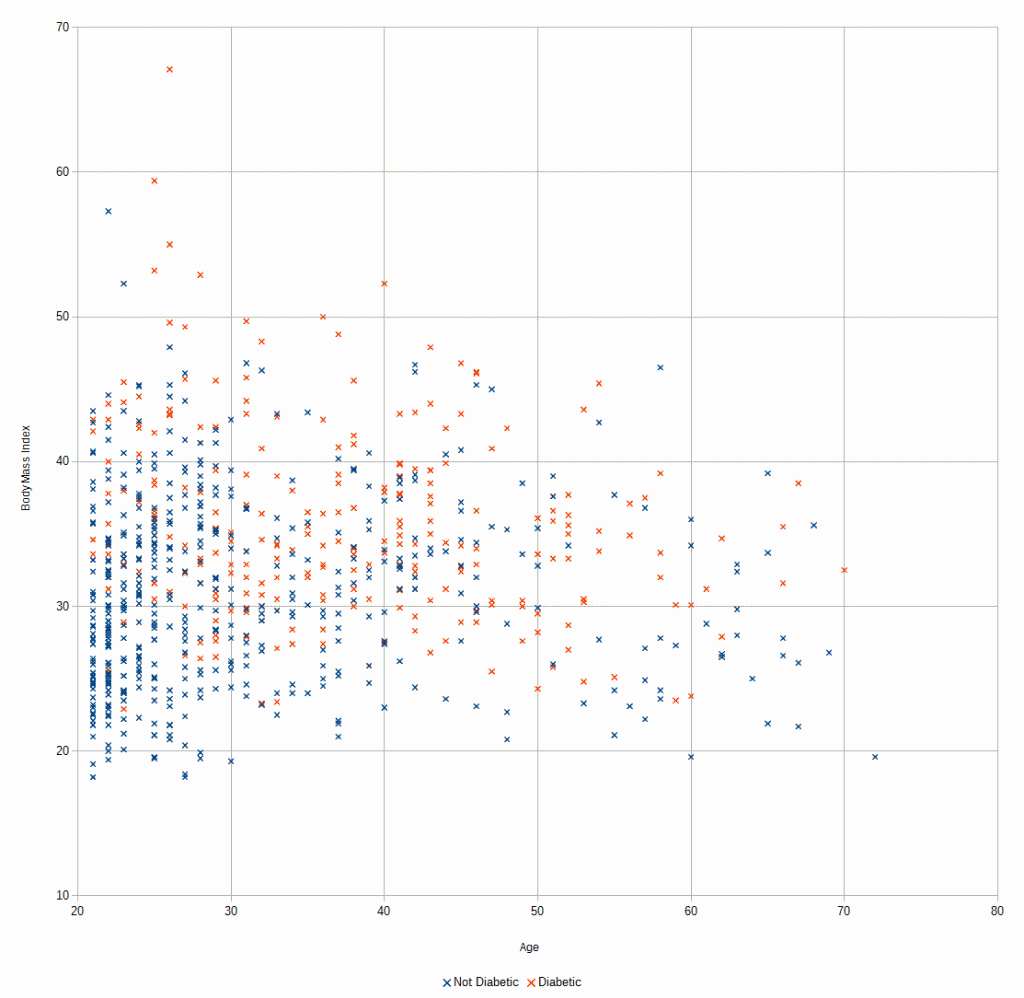
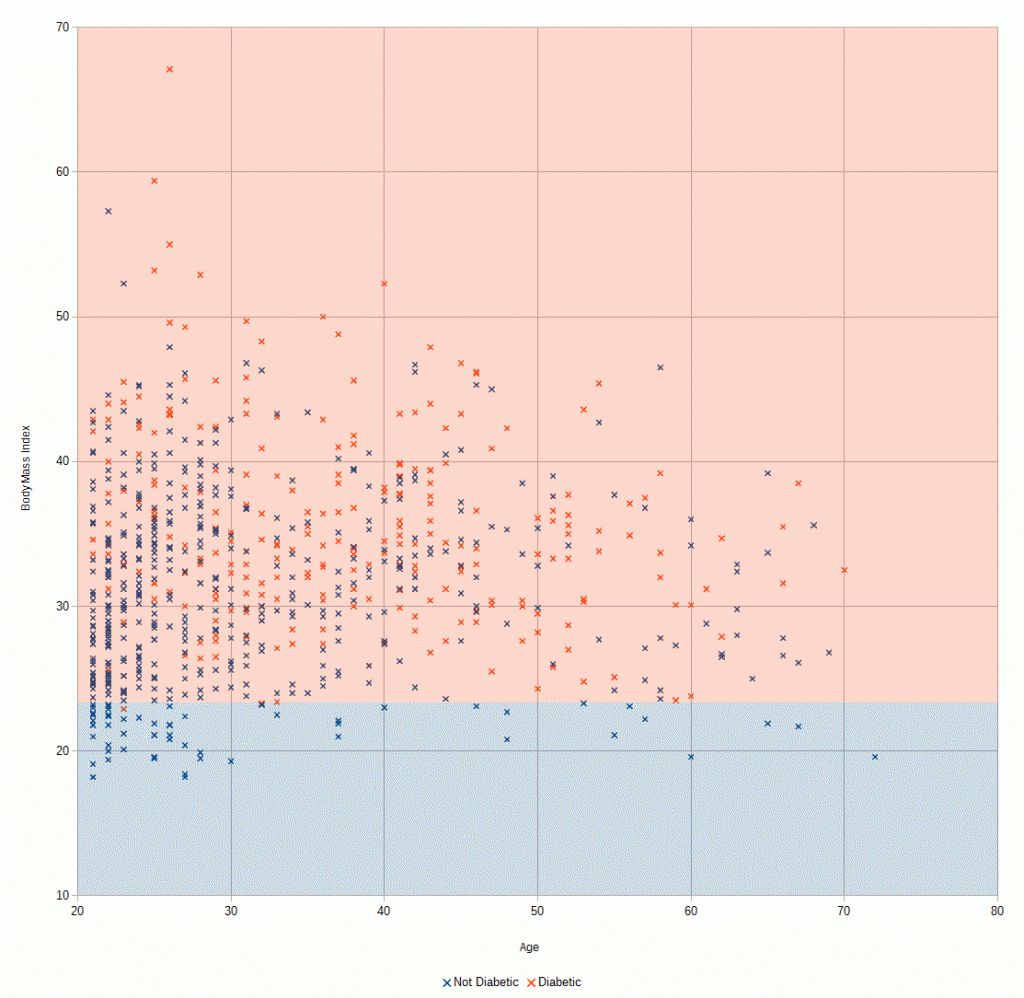
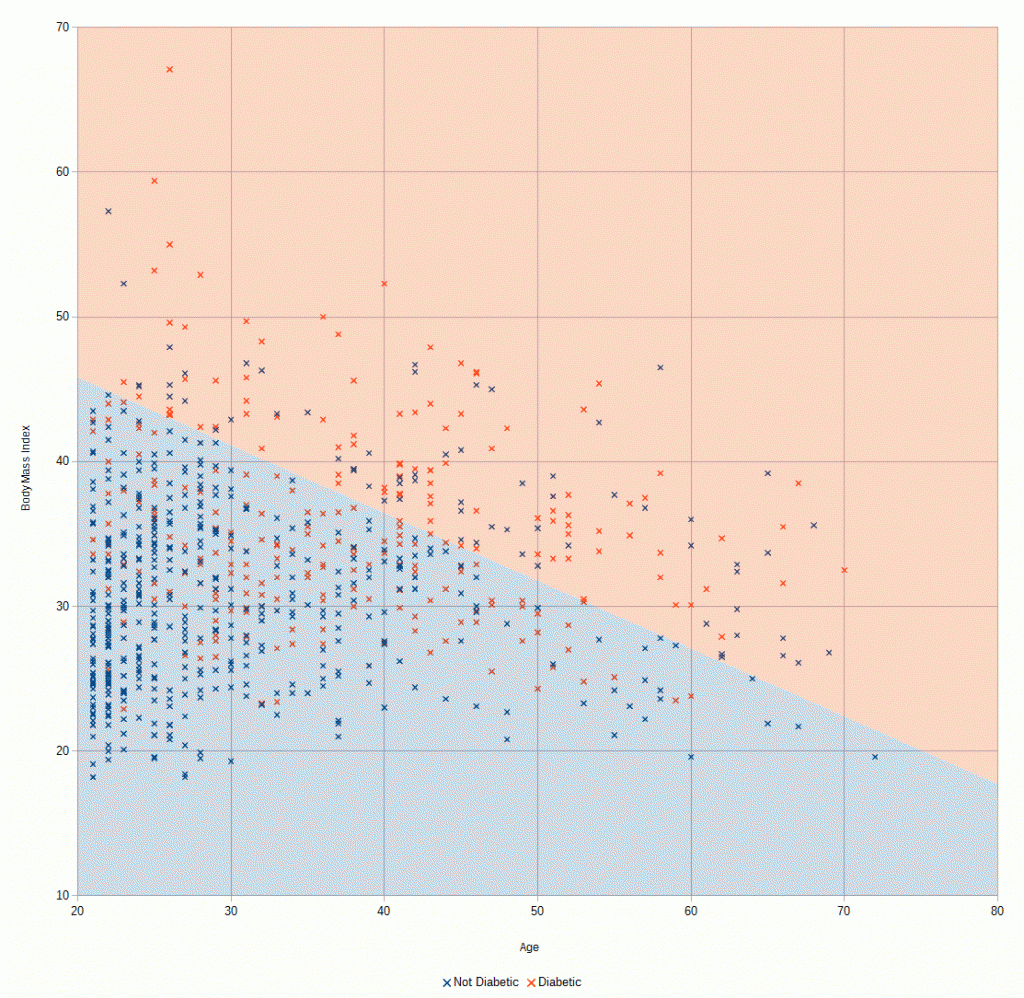
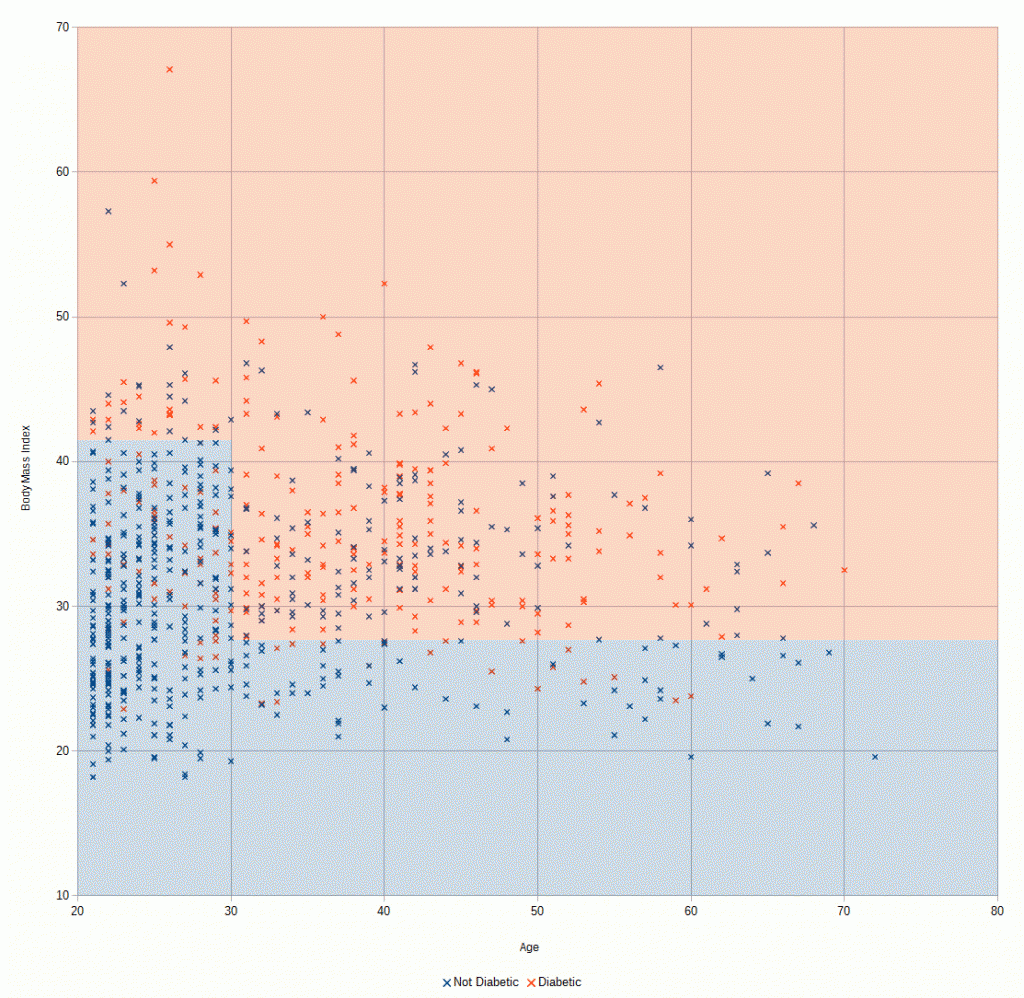
In another thread, I was talking about how most people have heard of Artificial Intelligence but have no idea what it actually is other than its some kind of hand-wavy techno-magic that makes computers smart.
Since I have a rather deep interest in the topic of AI (having a Masters in Machine Learning, was a PhD candidate for a while and was teaching assistant to Coursera's Stanford Machine Learning class for 2 years), I volunteered to provide a quick "Dummy's Guide" to Artificial Intelligence. It is a huge topic so I'm going to take it slowly with multiple posts over the next few weeks, but ultimately I hope to be able to answer these questions: What is AI? How does it work?What can it do? What can't it do?
By the way, feel free to ask any question. If I can answer it, I'll try. For now, I'll start by demystifying AI and briefly cover the history of AI.
Demystify Artificial Intelligence
Just like Physicists who occasionally declare to news reporters things like "We're unlocking the mysteries of the universe" or "The God Particle Discovered!", we Artificial Intelligence researchers are as guilty when it comes to glorifying our field of study. Anyone who has made in-depth study on AI know that our computers are neither smart nor intelligent. Really, a computer is just a glorified calculator. Yet, when it comes to reporters we still say inane things like, "Look at how smart and intelligent our AI is".
We may one day actually create an AI that can truly think and reason all by itself. However the truth is that at least for now, computers are still dumb. Remember, it is always a smart human that makes the dumb computer appear to do smart things. One day this might change and computers become truly intelligent. That's the holy grail of AI researchers, but at least for the next decade (or two) I don't believe things will change.
To be continued...
Since I have a rather deep interest in the topic of AI (having a Masters in Machine Learning, was a PhD candidate for a while and was teaching assistant to Coursera's Stanford Machine Learning class for 2 years), I volunteered to provide a quick "Dummy's Guide" to Artificial Intelligence. It is a huge topic so I'm going to take it slowly with multiple posts over the next few weeks, but ultimately I hope to be able to answer these questions: What is AI? How does it work?What can it do? What can't it do?
By the way, feel free to ask any question. If I can answer it, I'll try. For now, I'll start by demystifying AI and briefly cover the history of AI.
Demystify Artificial Intelligence
Just like Physicists who occasionally declare to news reporters things like "We're unlocking the mysteries of the universe" or "The God Particle Discovered!", we Artificial Intelligence researchers are as guilty when it comes to glorifying our field of study. Anyone who has made in-depth study on AI know that our computers are neither smart nor intelligent. Really, a computer is just a glorified calculator. Yet, when it comes to reporters we still say inane things like, "Look at how smart and intelligent our AI is".
We may one day actually create an AI that can truly think and reason all by itself. However the truth is that at least for now, computers are still dumb. Remember, it is always a smart human that makes the dumb computer appear to do smart things. One day this might change and computers become truly intelligent. That's the holy grail of AI researchers, but at least for the next decade (or two) I don't believe things will change.
To be continued...
Last edited:
")
")